Improving and Automating Build Failure Investigations Using Semantic Embeddings
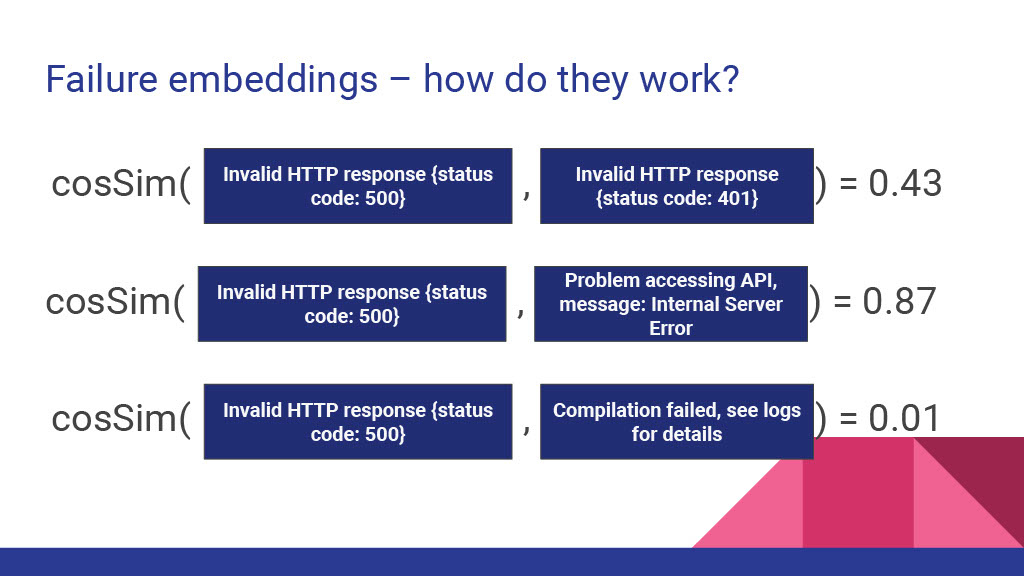
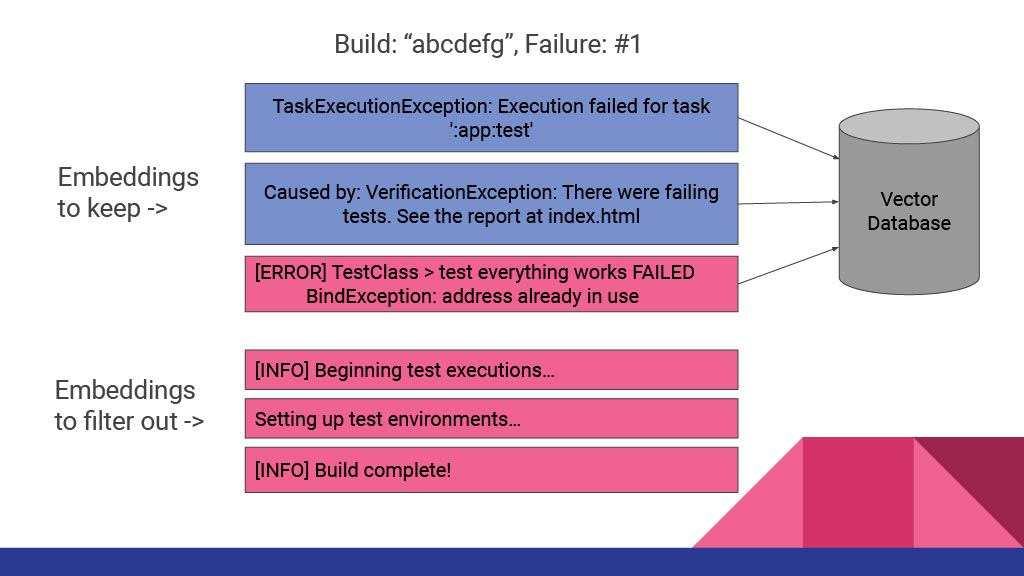
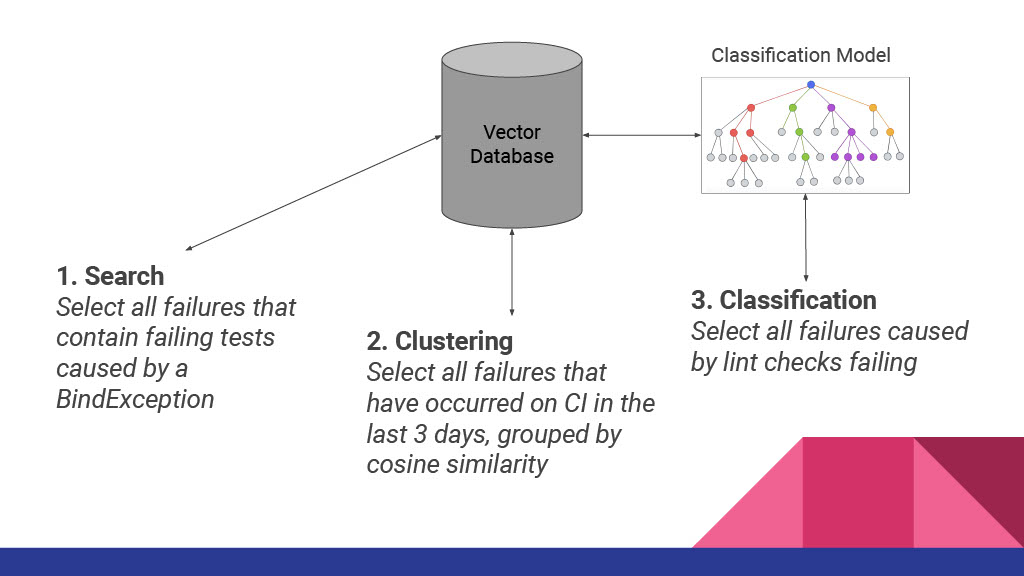
The process of tracking down and resolving build failures is a big pain point for many software development teams. Developers are often not sure what the actual cause of an observed build failure is, or if the failure they are seeing was caused by their changes or part of a larger problem. Infrastructure teams with several problems to solve often struggle to identify which problems are most impactful and thus should be resolved before others. Answering these questions often requires someone manually sifting through a large amount of available failure messages and log text what the cause of the failure was, which can be ineffective and/or time consuming. There must be a better way to automatically parse through the noise and find the information we’re looking for.
At Gradle we have been thinking a lot about how to better approach these problems using modern data science and AI modeling techniques. In this talk we’ll discuss our journey in researching this topic, and how our current methods are being used to improve Developer productivity within our organization.
-


Luke Daley
Executive Principal of Product & Technology and Develocity Co-Founder @ Gradle
-
Justin Merkel
Senior Data Scientist @ Gradle

Watch the video